Page d'information sur le portage GPU de LMDZ
Liste de liens divers
- la chaîne slack LMDZ/hackathon : https://lmdz.slack.com/archives/C01TGQWR6J2
- la chaîne mattermost 'Portage accélérateurs' : https://mattermost.lmd.ipsl.fr/lmdz/channels/portage-accelerateurs
- le google doc de Thomas utilisé pendant le Hackathon: https://docs.google.com/document/d/1dSlVbJD1aMrB5wT-_TnYoMLUdaqSAfji1O8q_wzuDNE
- le cours de l'IDRIS sur openACC http://www.idris.fr/formations/openacc/
- le callgraph simplifié de la physique simplifiée portée sur GPU pendant le Hackathon avec les indications de gestion de données https://web.lmd.jussieu.fr/~fairhead/Hackathon/callgraph_simplephysics.png
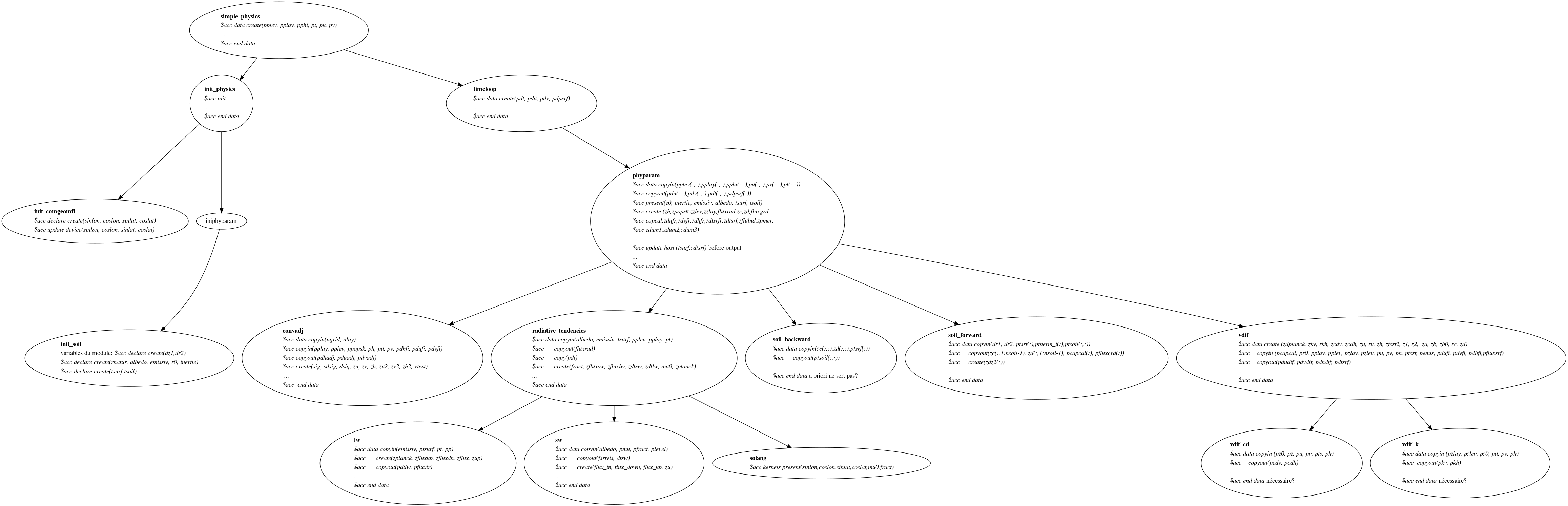{kind=link}
Règles de codage / portage
Traitement des DATA
- Déclarer en
!$acc data create (...)les variablesALLOCATABLEd'un module. Elles seront déclarées en!$acc data present (...)dans tous les modules les utilisant - Au début d'une routine:
- déclarer en
!$acc data create (...)les tableaux locaux - déclarer en
!$acc data copyin (...)les tableaux en argument qui sontintent(IN) - déclarer en
!$acc data copyout (...)les tableaux en argument qui sontintent(OUT) - déclarer en
!$acc data copy (...)les tableaux en argument qui sontintent(INOUT)
- déclarer en
- Pour les variables de modules:
- On peut rajouter systématiquement après un
!$OMP THREADPRIVATE(...)le!$acc declare create()correspondant, e.g.REAL, SAVE, ALLOCATABLE :: t_seri(:,:), q_seri(:,:) !$OMP THREADPRIVATE(t_seri, q_seri) !$acc declare create(t_seri, q_seri)
- On peut rajouter systématiquement après un
Mode d'emploi pour installer la branche portée sur jean-zay-pp
La branche est ici: https://svn.lmd.jussieu.fr/LMDZ/LMDZ6/branches/Portage_acc et on y commet donc les modifications aux routines concernant le portage.
Exemple d'installation
A priori, on a juste besoin d'une librairie IOIPSL compilée avec la bonne version du compilateur NVIDIA. J'installe le modèle par modipsl en utilisant la configuration LMDZOR_v6.2_work. Je crée les arch qu'il faut pour IOIPSL et je recompile la libraire IOIPSL (sachant qu'il y a une modif à faire dans src/getincom.f90. Voir chez moi dans $WORK/LMDZ_NVIDIA sur jean-zay-pp).
Ensuite on checkout la version de LMDZ qui va bien et on compile:
# Récupération du modèle cd .../modeles mv LMDZ LMDZ.orig svn checkout https://svn.lmd.jussieu.fr/LMDZ/LMDZ6/branches/Portage_acc LMDZ cd LMDZ # Compilation . ./arch.env ./makelmdz_fcm -d 32x32x39 -p lmd -rrtm false -prod -parallel none -io ioipsl -veget none -arch X64_JEANZAY_GPU -j 8 gcm
On récupère ensuite le bench à la bonne résolution pour faire les tests d'exécution
Portage des routines individuelles
La méthode replay
La ré-écriture des différentes routines des paramétrisations de la physique selon un certain format permet de rejouer (d'où le mode replay) la paramétrisation de façon individuelle mais réaliste puisque qu'on sauvegarde ses entrées-sorties lors d'un vrai run 1D/3D et qu'on peut donc tester la routine à partir de ces données réalistes et une simple boucle dans le temps.
Ici, ce mode nous permet donc de:
- sauvegarder les données d'entrée de la paramétrisation dans sa version originale et les résultats obtenus quand on la fait tourner
- faire tourner la version portée par openacc dans les mêmes conditions et comparer les résultats obtenus avec la version openacc avec ceux obtenus précédemment.
En revanche, si la méthode par défaut nous permet de vérifier que les résultats sont les mêmes entre une exécution CPU et une exécution GPU, elle ne nous permet pas de vérifier le gain en temps du passage au GPU vu qu'on lit tous les champs d'entrée à partir d'un fichier à chaque pas de temps et qu'il faut donc les transférer du CPU au GPU à chaque pas de temps en perdant ainsi le bénéfice de l'accélération GPU. Une adaptation du programme principal où on ne lirait les champs d'entrée qu'au premier pas de temps en bouclant sur les mêmes champs sur tous les pas de temps devrait permettre de mesurer la performance.
Proposition de méthodologie
Une fois la mécanique "replay" mise en place, on passe par les étapes suivantes:
- on outille les boucles de la paramétrisation avec des
!$acc kernelssans se soucier de l'aspect 'gestion de données', dans un premier temps on laisse le compilateur s'en occuper. On teste les modifications sur un pas de temps (avec le replay3d modifié) en comparant les sorties de phys.nc entre un run cpu et un run gpu jusqu'à ce qu'on soit content du résultat (a priori les deux phys.nc doivent être les mêmes) - une fois l'étape 1 réussie, on commence à outiller la paramétrisation en directives de gestion des données, et on continue à les tester en mode comparaison de 1 pas de temps cpu/gpu jusqu'à être content du résultat
- à ce stade, on peut lancer des runs sur plusieurs pas sans input ni output, pour mesurer les performances.
Les routines replay3d et call_param_replay ont été modifiées pour pouvoir, interactivement :
- rentrer le nombre de fois à passer dans la boucle principale
- décider si on lit le fichier input à chaque passage dans la boucle ou si on se contente de repasser en boucle les paramètres correspondant au 1er pas de temps
- décider si on sort le fichier phys.nc ou non